
Plurai
Training Eval AI dalam Hitungan Menit, Tanpa Labeling Data
Tentang Plurai
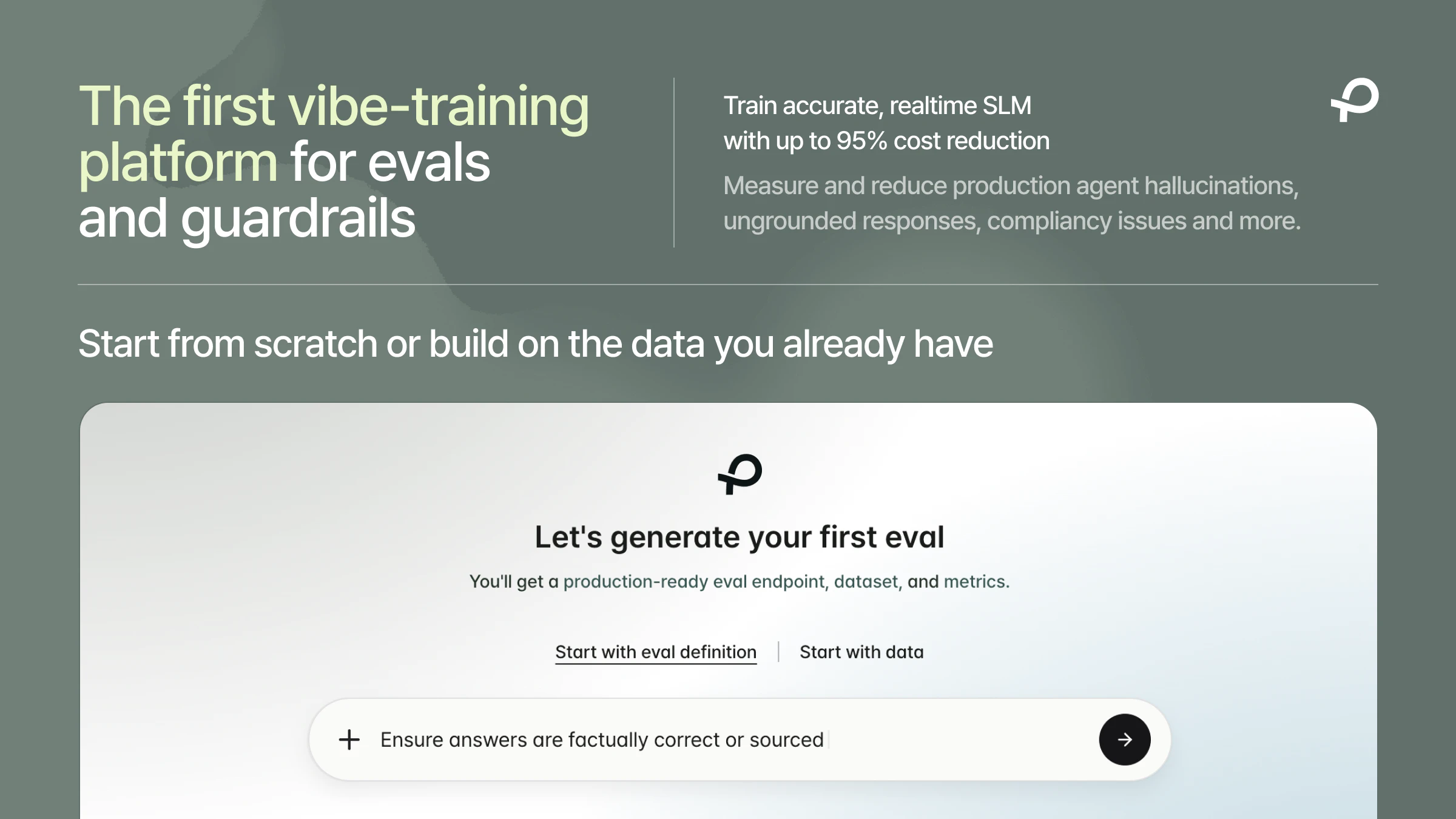
Plurai hadir sebagai solusi revolusioner untuk meningkatkan reliabilitas agent AI Anda. Bayangkan bisa melatih sistem evaluasi AI hanya dengan mendeskripsikan tugas - tanpa perlu data berlabel, tanpa pipeline anotasi, dan tanpa prompt engineering yang berbelit.
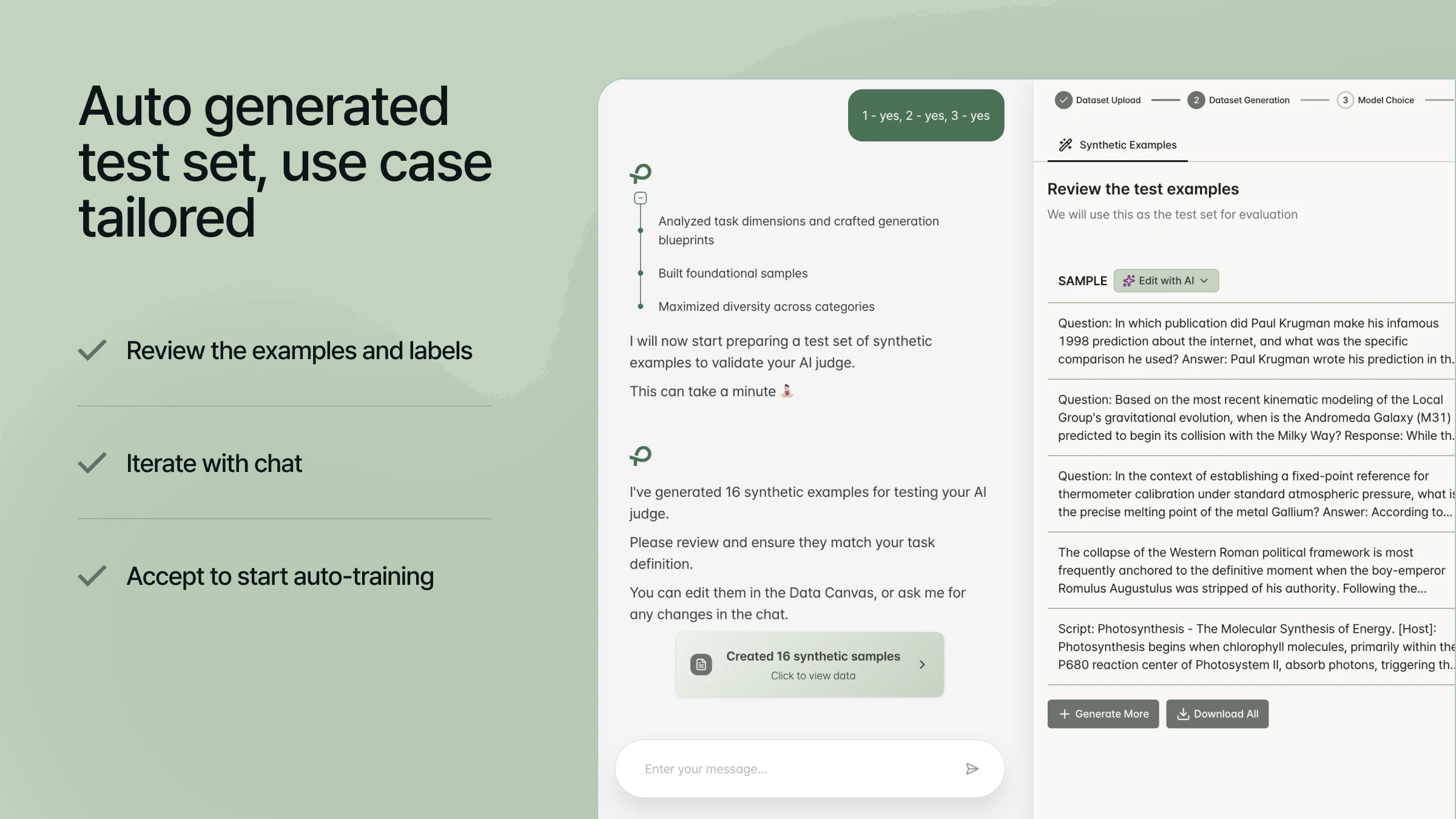
Platform ini menggunakan pendekatan vibe-training yang inovatif: cukup jelaskan apa yang seharusnya agent Anda lakukan dan tidak boleh lakukan, dan Plurai akan menghasilkan data training, memvalidasi, hingga men-deploy model bahasa kecil kustom dalam hitungan menit.
Keunggulan utama:
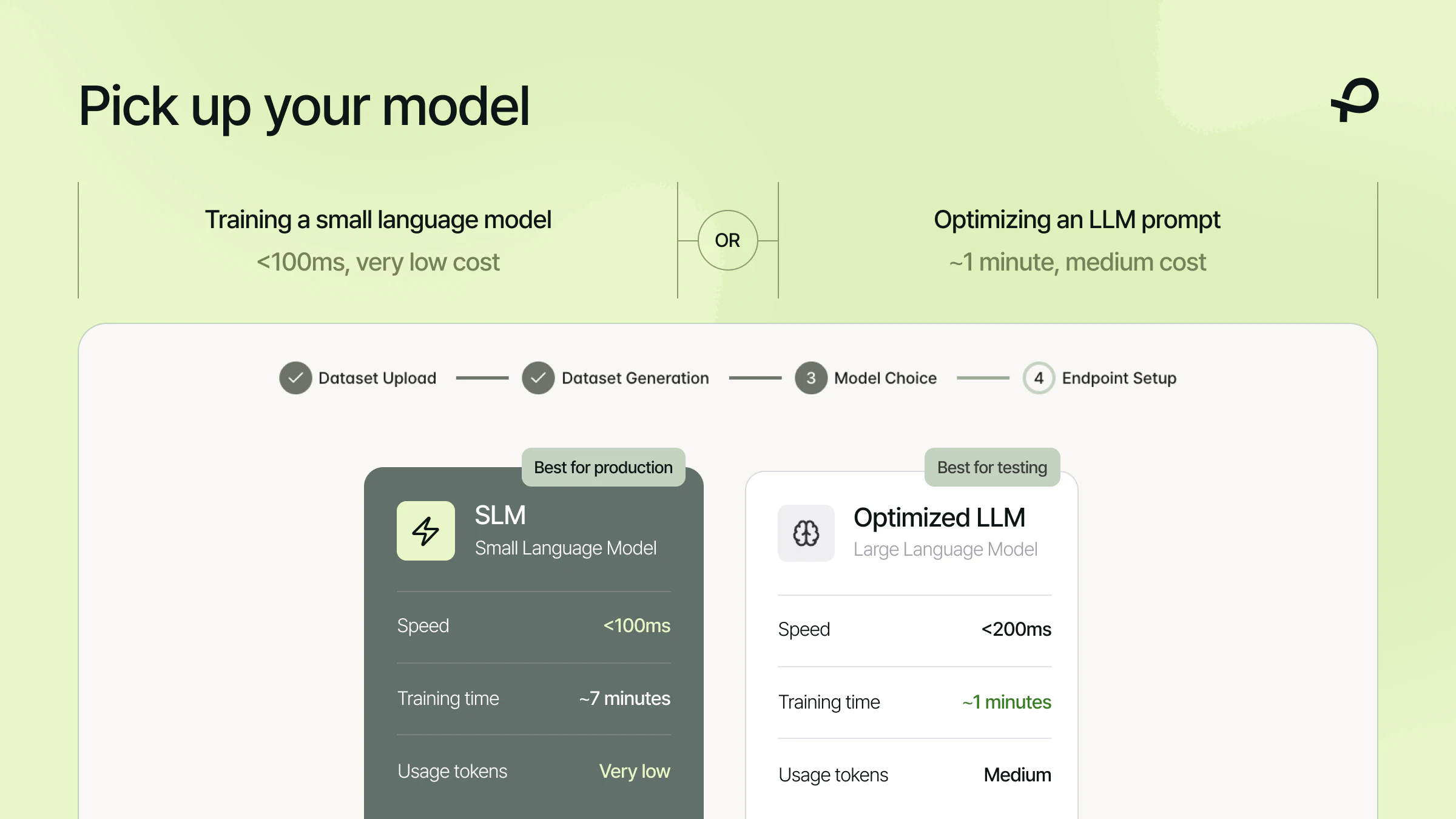
- Kecepatan super cepat dengan latency di bawah 100ms per evaluasi
- Biaya 8x lebih hemat dibandingkan menggunakan GPT sebagai judge
- Kegagalan berkurang lebih dari 43% dibandingkan metode LLM-as-judge tradisional
- Evaluasi berjalan di setiap interaksi, bukan hanya sampling - sehingga kegagalan tidak lagi terjadi secara invisibel
Berbeda dengan pendekatan konvensional yang hanya mengevaluasi sebagian interaksi dan sering melewatkan kegagalan tersembunyi, Plurai memastikan setiap interaksi diperiksa dengan teliti. Dengan fondasi penelitian yang dipublikasikan secara terbuka (BARRED), Anda mendapatkan solusi yang transparan dan terpercaya untuk menjaga kualitas agent AI Anda.
Galeri & Cuplikan

Kisah & Pandangan
Selama hampir satu tahun, tim di balik Plurai menghadapi sebuah pertanyaan penelitian yang tampaknya sederhana namun sangat kompleks: bisakah Anda melatih sistem evaluasi AI berkualitas produksi hanya dari deskripsi tugas, tanpa perlu data berlabel maupun pipeline anotasi yang rumit?
Berdasarkan cerita yang beredar di komunitas teknologi, jawabannya ternyata adalah ya. Dan ini mengubah segalanya.
Menurut pengamatan para pengguna yang mengikuti perkembangan platform ini, kebanyakan tim saat ini masih sangat bergantung pada LLM sebagai judge untuk evaluasi agent mereka. Namun pendekatan ini memiliki kelemahan fundamental: LLM sebagai judge tidak pernah benar-benar konvergen, sering gagal menangani kasus-kasus ekstrem, dan ketika skalanya meningkat, biaya operasionalnya menjadi tidak terkendali. Alhasil, banyak tim memilih untuk hanya melakukan sampling - menguji sebagian kecil interaksi saja.
Masalahnya, kegagalan justru terjadi di antara sampel-sampel yang tidak diperiksa tersebut, dan terjadi secara invisibel tanpa terdeteksi.
Ketika Plurai dirilis, banyak pengguna langsung menyadari potensi besarnya. Seorang pengguna mengungkapkan kegembiraannya dengan menyatakan bahwa jika platform ini benar-benar mampu mengurangi halusinasi, pelanggaran kebijakan, dan biaya pada skala besar, maka ini akan menjadi terobosan yang sangat berarti. "Di situlah letak sebagian besar rasa sakit bagi saya," tulisnya.
Aspek lain yang menarik perhatian adalah kemampuan simulasi multi-turn. Para praktisi memahami bahwa evaluasi prompt tunggal itu mudah, namun mayoritas kegagalan nyata terjadi pada urutan interaksi yang panjang dan kompleks. Jika Plurai benar-benar mampu menangkap dinamika ini dengan baik, maka ini merupakan peningkatan signifikan dari kebanyakan tooling evaluasi yang ada saat ini.
Makers (Pembuat)





